渗透测试-信息收集工具介绍
![]()
渗透测试-信息收集工具介绍
1 渗透测试-信息收集方式分类

1)服务器的相关信息(真实ip,系统类型,版本,开放端口,WAF等)
2)网站指纹识别(包括,cms,cdn,证书等)dns记录
3)whois信息,姓名,备案,邮箱,电话反查(邮箱丢社工库,社工准备等)
4)子域名收集,旁站,C段等
5)google hacking针对化搜索,word/电子表格/pdf文件,中间件版本,弱口令扫描等
6)扫描网站目录结构,爆后台,网站banner,测试文件,备份等敏感文件泄漏等
7)传输协议,通用漏洞,exp,github源码等
2 域名收集-whois
2.1 whois信息在线查询网站
1 | |
2.2 kail whois使用说明
使用kali系统自带的whois 命令:查询域名相关信息,可以收集注册公司、注册邮箱、注册人信息、子域名
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22]$ whois hesc.info
Domain Name: HESC.INFO
Registry Domain ID: D503300001182406222-LRMS
Registrar WHOIS Server:
Registrar URL: http://www.net.cn
Updated Date: 2020-05-28T21:22:34Z
Creation Date: 2019-11-27T02:25:39Z
Registry Expiry Date: 2024-11-27T02:25:39Z
Registrar Registration Expiration Date:
Registrar: Alibaba Cloud Computing (Beijing) Co., Ltd.
Registrar IANA ID: 420
Registrar Abuse Contact Email: DomainAbuse@service.aliyun.com
Registrar Abuse Contact Phone: +86.95187
Reseller:
Domain Status: ok https://icann.org/epp#ok
Registrant Organization: ****
Registrant State/Province: 上海
Registrant Country: CN
Name Server: DNS3.HICHINA.COM
Name Server: DNS4.HICHINA.COM
DNSSEC: unsigned
URL of the ICANN Whois Inaccuracy Complaint Form: https://www.icann.org/wicf/
2.3 通过公司名称获取域名
FOFA title=”公司名称”
百度 intitle=公司名称
Google intitle=公司名称
站长之家,直接搜索名称或者网站域名即可查看相关信息:http://tool.chinaz.com/
钟馗之眼 site=域名即可:https://www.zoomeye.org/
2.4 DNS侦测<强烈推荐>
3 子域名收集
3.1 在线子域名收集
https://phpinfo.me/domain/
https://www.t1h2ua.cn/tools/
https://site.ip138.com/moonsec.com/domain.htm
https://fofa.so/ 语法:domain=”baidu.com”
https://hackertarget.com/find-dns-host-records/ Hackertarget查询子域名: 通过该方法查询子域名可以得到一个目标大概的ip段,接下来可以通过ip来收集信息。
https://quake.360.cn/ 语法:domain:”*.freebuf.com”
https://securitytrails.com/list/apex_domain/根域名
https://tool.chinaz.com/subdomain/hesc.info
3.2 域名收集工具
3.2.1 Layer

3.2.2 SubDomainBrute
使用python开发,使用Python3运行,需要安装aiodns库
解决依赖:pip3 install aiodns
使用介绍
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Usage: subDomainsBrute.py [options] target.com
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-f FILE File contains new line delimited subs, default is
subnames.txt.
--full Full scan, NAMES FILE subnames_full.txt will be used
to brute
-i, --ignore-intranet
Ignore domains pointed to private IPs
-w, --wildcard Force scan after wildcard test fail
-t THREADS, --threads=THREADS
Num of scan threads, 256 by default
-p PROCESS, --process=PROCESS
Num of scan Process, 6 by default
-o OUTPUT, --output=OUTPUT
Output file name. default is {target}.txt
运行命令
2python3 subDomainsBrute.py freebuf.com
python3 subDomainsBrute.py freebuf.com --full -o freebuf2.txt
3.2.3 Sublist3r
官网地址:https://github.com/aboul3la/Sublist3r
解决依赖:pip install -r requirements.txt
中文说明:
2
3
4
5
6
7
8
9
10
11
12
13-h :帮助
-d :指定主域名枚举子域名
-b :调用subbrute暴力枚举子域名
-p :指定tpc端口扫描子域名
-v :显示实时详细信息结果
-t :指定线程
-e :指定搜索引擎
-o :将结果保存到文本
-n :输出不带颜色
kali@kali:/opt/Sublist3r$ python3 sublist3r.py -d qq.com -b -o qq.txt
kali@kali:/opt/Sublist3r$ python3 sublist3r.py -d moonsec.com
kali@kali:/opt/Sublist3r$ python3 sublist3r.py -d -b moonsec.com -p 80,443 -v -o monsec.com.txt
kali@kali:/opt/Sublist3r$ python3 sublist3r.py -d moonsec.com -b -o moonsec.com.txt
1 | |
3.2.4 OneForALL
网站:https://github.com/shmilylty/OneForAll
要求:OneForAll需要高于Python 3.6.0的版本才能运行
解决依赖:
2
3>cd OneForAll/
kali@kali:/opt/Sublist3r$ python3 -m pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
>kali@kali:/opt/Sublist3r$ pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
使用例子
2kali@kali:/opt/Sublist3r$ python3 oneforall.py --target example.com run
kali@kali:/opt/Sublist3r$ python3 oneforall.py --targets ./example.txt run
使用介绍
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52kali@kali:/opt/Sublist3r$ python3 oneforall.py --help
NAME
oneforall.py - OneForAll帮助信息
SYNOPSIS
oneforall.py COMMAND | --target=TARGET <flags>
DESCRIPTION
OneForAll是一款功能强大的子域收集工具
Example:
python3 oneforall.py version
python3 oneforall.py --target example.com run
python3 oneforall.py --targets ./domains.txt run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --port small run
python3 oneforall.py --target example.com --fmt csv run
python3 oneforall.py --target example.com --dns False run
python3 oneforall.py --target example.com --req False run
python3 oneforall.py --target example.com --takeover False run
python3 oneforall.py --target example.com --show True run
Note:
参数alive可选值True,False分别表示导出存活,全部子域结果
参数port可选值有'default', 'small', 'large', 详见config.py配置
参数fmt可选格式有 'csv','json'
参数path默认None使用OneForAll结果目录生成路径
ARGUMENTS
TARGET
单个域名(二选一必需参数)
TARGETS
每行一个域名的文件路径(二选一必需参数)
FLAGS
--brute=BRUTE
s
--dns=DNS
DNS解析子域(默认True)
--req=REQ
HTTP请求子域(默认True)
--port=PORT
请求验证子域的端口范围(默认只探测80端口)
--valid=VALID
只导出存活的子域结果(默认False)
--fmt=FMT
结果保存格式(默认csv)
--path=PATH
结果保存路径(默认None)
--takeover=TAKEOVER
检查子域接管(默认False)
3.2.5 wydomain
网站:https://github.com/ring04h/wydomain
记得每次运行前git pull一下,有空的话都会修bug.
chaxun.la 对请求频率过高的ip,要人工输入验证码,代码嵌入了[云速打码]自动识别验证码的功能,但是多人公用账号,导致我的账号被封禁了,所以临时关闭人机绕过功能,如果需要开启,你们可以注册使用自己账号。
解决依赖:
kali@kali:/opt/Sublist3r$ pip install -r requirements.txt
使用例子
2
3
4$ python3 dnsburte.py -d aliyun.com -f dnspod.csv -o aliyun.log
2016-11-01 13:01:02,327 [INFO] starting bruteforce threading(16) : aliyun.com
2016-11-01 13:02:15,985 [INFO] dns bruteforce subdomains(51) successfully...
2016-11-01 15:03:43,367 [INFO] result save in : aliyun.log
使用介绍
2
3
4
5
6
7
8
9
10
11$ python dnsburte.py -h
usage: dnsburte.py [-h] [-t] [-d] [-f] [-o]
wydomian v 2.0 to bruteforce subdomains of your target domain.
optional arguments:
-h, --help show this help message and exit
-t , --thread thread count
-d , --domain domain name
-f , --file subdomains dict file name
-o , --out result out file
字典名称 说明 default.csv top 200 子域名字典 dnstop.csv dnspod.com 官方提供的top 2000条子域名字典 wydomain.csv wyodmian 1.0 的top 3000子域名字典 (非常高效) wydomian 1.0 大字典 https://github.com/ring04h/wydomain/blob/master/domain_larger.csv
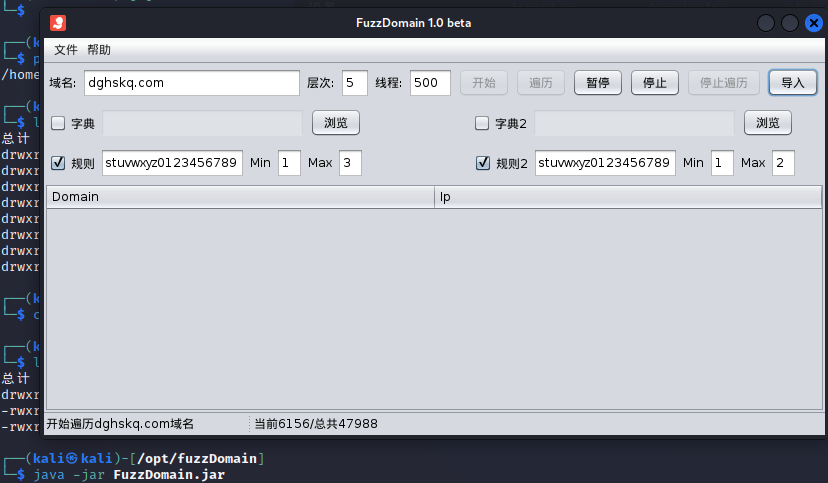
3.2.6 FuzzDomain
官网地址:https://github.com/Chora10/FuzzDomain
使用Java开发,有图形界面。可视化操作。
java -jar FuzzDomain.jar
4 端口扫描
4.1 masscan
网站:https://github.com/zan8in/masscan
说明:kali自带
1 | |
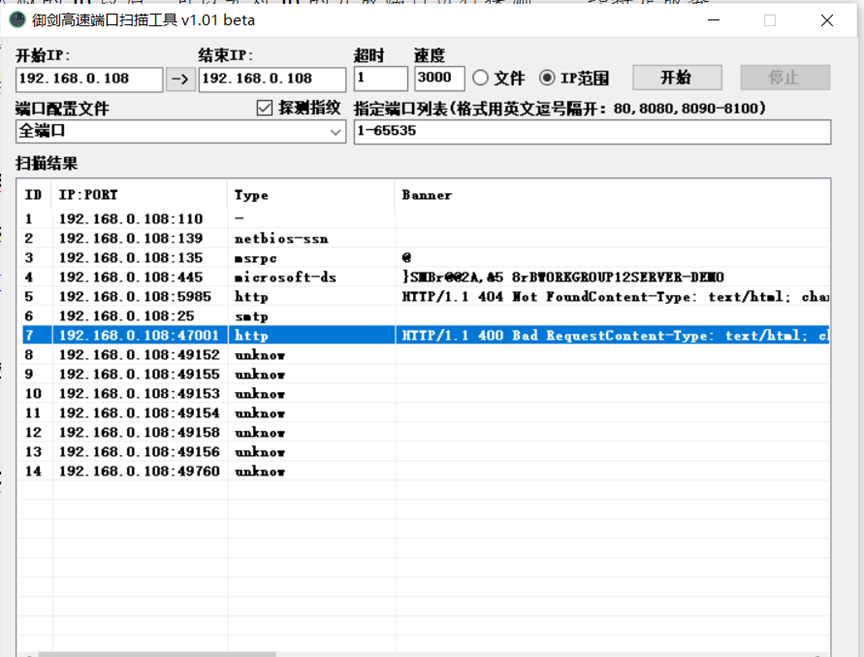
4.2 御剑端口扫描
4.3 nmap
网站:https://github.com/nmap/nmap
说明:kali自带,支持网段扫描、支持TCP、UDP端口。非常厉害的端口扫描工具,可以识别端口启用的服务信息。就是没有中文介绍
使用参数说明:语法:nmap [扫描类型] [选项] {目标规范}
参数 说明 -sT TCP协议端口 -sU UDP协议端口 -p 指定端口范围 -sV 版本检测扫描 -A 命令混合式扫描。OS识别,版本探测,脚本扫描和traceroute综合扫描 -sC 等价于=–script 使用具体脚本进行扫描 -iL 导入ip或域名文件清单列表进行扫描 -oX 导出扫描结果为xml格式 详细选项说明见:nmap超详细使用教程_刘—手的博客-CSDN博客
1 | |
1 | |
4.4 在线端口扫描
5 C段和旁站信息收集
5.1 旁站
同IP网站查询:
5.2 C段
旁站查询:
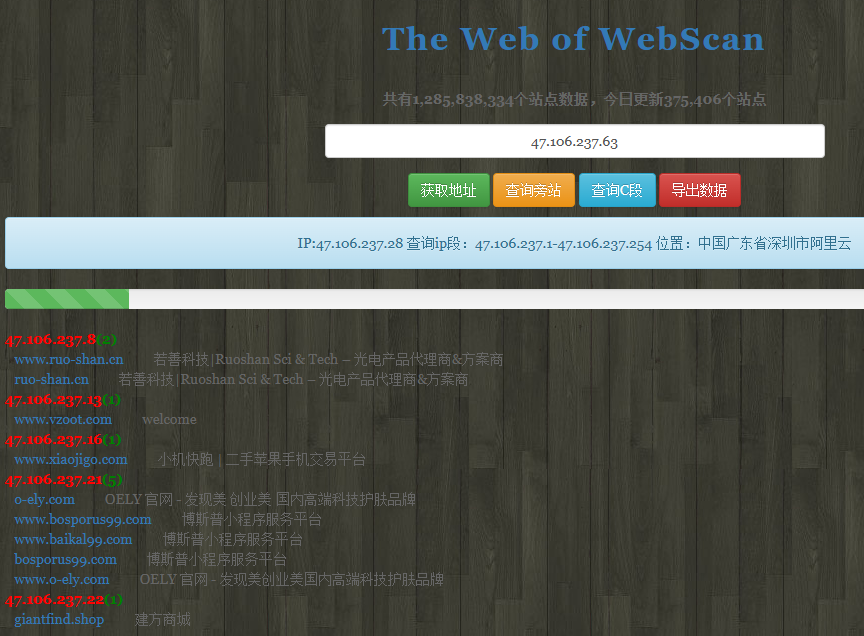
暗月师傅基于c.webscan.cc网站API接口开发的Python脚本,扫描C段和旁站的web服务。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27$ python3 旁站查询.py
请你输入要查询的ip:47.106.237.63
请你输入要查询的ip:47.106.237.63
正在收集47.106.237.1
正在收集47.106.237.2
正在收集47.106.237.3
正在收集47.106.237.4
正在收集47.106.237.5
正在收集47.106.237.6
......
正在收集47.106.237.31
[+] www.weixue100.com 威学教育_威学托福_威学一百_托福、威学雅思_托福培训课程[+]
[+] www.topuis.cn 宝莎韬优国际学校,直通全球前80大学,入读可全免三年学费[+]
[+] topuis.cn [+]
[+] weixue100.com 威学教育_威学托福_威学一百_托福、威学雅思_托福培训课程[+]
[+] wishare100.com 威学教育_威学托福_威学一百_托福、威学雅思_托福培训课程[+]
[+] wap.weixue100.com [+]
[+] guojixuexiao100.com [+]
[+] www.zhima101.com 广州国际高中_国际初中_国际班入学考试_国际学校择校指导-芝麻择校[+]
[+] wishare100.cn [+]
[+] www.wiwikid.com 国际英语·开启国际教育大门 国际学校规划、择校辅导、留学规划[+]
[+] zhima101.com 广州国际高中_国际初中_国际班入学考试_国际学校择校指导-芝麻择校[+]
[+] zexiao101.com [+]
[+] www.zexiao101.com [+]
[+] www.wishare100.com 威学教育_威学托福_威学一百_托福、TOEFL备考复习攻略_托福培训班课程、雅思的出国考试在线培训平台[+]
[+] news.weixue100.com 国际高中_国际初中_国际班入学考试_国际学校择校指导-芝麻择校[+]
[+] wiwikid.com [+]
5.2.1 scanner.py
使用python2开发
1 | |
5.2.2 使用nmap扫描网站
1 | |
常见的web服务端口
1 | |
6 网站目录和文件扫描
6.1 御剑后台扫描工具
不怎么好用,当扫描频率过高会被waf防御。导致浏览器访问重定向。
解决方法:搭建IP代理词池、使用相关扫描软件过waf。
1 | |
6.2 DirBuster
纯英文界面,扫描速度快,支持自定义字典、自定义文件后缀名
6.3 7kbscan-WebPathBrute
中文操作界面,扫描速度快,支持设置http_user_agent
6.4 bbscan
https://gitee.com/mirrors/bbscan
使用Python开发,运行环境Python3
git clone https://gitee.com/mirrors/bbscan.git
pip3 install -r requirements.txt
使用帮助
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51┌──(root㉿kali)-[/opt/bbscan]
└─# python3 BBScan.py
usage: BBScan.py [options]
* A fast vulnerability Scanner. *
* Find sensitive info disclosure vulnerabilities from large number of targets *
By LiJieJie (http://www.lijiejie.com)
options:
-h, --help show this help message and exit
Targets:
--host [HOST ...] Scan several hosts from command line
-f TargetFile Load new line delimited targets from TargetFile
-d TargetDirectory Load all *.txt files from TargetDirectory
--crawler CrawlDirectory
Load all *.log crawl files from CrawlDirectory
--network MASK Scan all Target/MASK neighbour hosts,
should be an integer between 8 and 31
HTTP SCAN:
--rule [RuleFileName ...]
Import specified rule files only.
-n, --no-crawl No crawling, sub folders will not be processed
-nn, --no-check404 No HTTP 404 existence check
--full Process all sub directories
Scripts SCAN:
--scripts-only Scan with user scripts only
--script [ScriptName ...]
Execute specified scripts only
--no-scripts Disable all scripts
CONCURRENT:
-p PROCESS Num of processes running concurrently, 30 by default
-t THREADS Num of scan threads for each scan process, 3 by default
OTHER:
--proxy Proxy Set HTTP proxy server
--timeout Timeout Max scan minutes for each target, 10 by default
-md Save scan report as markdown format
--save-ports PortsDataFile
Save open ports to PortsDataFile
--debug Show verbose debug info
-nnn, --no-browser Do not open web browser to view report
-v show program's version number and exit
1 | |
6.5 dirmap
网站:https://github.com/H4ckForJob/dirmap
说明:一个高级web目录扫描工具,功能将会强于DirBuster、Dirsearch、cansina、御剑,
扫描结果保存在dirmap/outputs目录下安装步骤:
2
3git clone https://github.com/H4ckForJob/dirmap.git
cd dirmap
python3 -m pip install -r requirement.txt
使用例子:
2单个目标:python3 dirmap.py -i https://target.com -lcf
多个目标:python3 dirmap.py -iF urls.txt -lcf
使用帮助:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24└─# python3 dirmap.py -h
##### # ##### # # ## #####
# # # # # ## ## # # # #
# # # # # # ## # # # # #
# # # ##### # # ###### #####
# # # # # # # # # #
##### # # # # # # # # v1.0
usage: python3 dirmap.py -i https://target.com -lcf
options:
-h, --help show this help message and exit
Engine:
Engine config
-t THREAD_NUM, --thread THREAD_NUM
num of threads, default 30
Target:
Target config
-i TARGET scan a target or network (e.g. [http://]target.com , 192.168.1.1[/24] , 192.168.1.1-192.168.1.100)
-iF FILE load targets from targetFile (e.g. urls.txt)
Bruter:
Bruter config
-lcf, --loadConfigFile
Load the configuration through the configuration file
--debug Print payloads and exit
6.6 dirsearch
网站:https://github.com/maurosoria/dirsearch
说明:高级网络路径暴力破解程序
安装:
2
3>git clone https://github.com/maurosoria/dirsearch.git --depth 1
>cd dirsearch
>pip3 install -r requirements.txt
使用例子:
sudo python3 dirsearch.py -u http://typecho.run/ -e php,jsp,html
使用帮助:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150Usage: dirsearch.py [-u|--url] target [-e|--extensions] extensions [options]
Options:
--version show program's version number and exit
-h, --help show this help message and exit
Mandatory:
-u URL, --url=URL Target URL(s), can use multiple flags
-l PATH, --url-file=PATH
URL list file
--stdin Read URL(s) from STDIN
--cidr=CIDR Target CIDR
--raw=PATH Load raw HTTP request from file (use '--scheme' flag
to set the scheme)
-s SESSION_FILE, --session=SESSION_FILE
Session file
--config=PATH Path to configuration file (Default:
'DIRSEARCH_CONFIG' environment variable, otherwise
'config.ini')
Dictionary Settings:
-w WORDLISTS, --wordlists=WORDLISTS
Customize wordlists (separated by commas)
-e EXTENSIONS, --extensions=EXTENSIONS
Extension list separated by commas (e.g. php,asp)
-f, --force-extensions
Add extensions to the end of every wordlist entry. By
default dirsearch only replaces the %EXT% keyword with
extensions
-O, --overwrite-extensions
Overwrite other extensions in the wordlist with your
extensions (selected via `-e`)
--exclude-extensions=EXTENSIONS
Exclude extension list separated by commas (e.g.
asp,jsp)
--remove-extensions
Remove extensions in all paths (e.g. admin.php ->
admin)
--prefixes=PREFIXES
Add custom prefixes to all wordlist entries (separated
by commas)
--suffixes=SUFFIXES
Add custom suffixes to all wordlist entries, ignore
directories (separated by commas)
-U, --uppercase Uppercase wordlist
-L, --lowercase Lowercase wordlist
-C, --capital Capital wordlist
General Settings:
-t THREADS, --threads=THREADS
Number of threads
-r, --recursive Brute-force recursively
--deep-recursive Perform recursive scan on every directory depth (e.g.
api/users -> api/)
--force-recursive Do recursive brute-force for every found path, not
only directories
-R DEPTH, --max-recursion-depth=DEPTH
Maximum recursion depth
--recursion-status=CODES
Valid status codes to perform recursive scan, support
ranges (separated by commas)
--subdirs=SUBDIRS Scan sub-directories of the given URL[s] (separated by
commas)
--exclude-subdirs=SUBDIRS
Exclude the following subdirectories during recursive
scan (separated by commas)
-i CODES, --include-status=CODES
Include status codes, separated by commas, support
ranges (e.g. 200,300-399)
-x CODES, --exclude-status=CODES
Exclude status codes, separated by commas, support
ranges (e.g. 301,500-599)
--exclude-sizes=SIZES
Exclude responses by sizes, separated by commas (e.g.
0B,4KB)
--exclude-text=TEXTS
Exclude responses by text, can use multiple flags
--exclude-regex=REGEX
Exclude responses by regular expression
--exclude-redirect=STRING
Exclude responses if this regex (or text) matches
redirect URL (e.g. '/index.html')
--exclude-response=PATH
Exclude responses similar to response of this page,
path as input (e.g. 404.html)
--skip-on-status=CODES
Skip target whenever hit one of these status codes,
separated by commas, support ranges
--min-response-size=LENGTH
Minimum response length
--max-response-size=LENGTH
Maximum response length
--max-time=SECONDS Maximum runtime for the scan
--exit-on-error Exit whenever an error occurs
Request Settings:
-m METHOD, --http-method=METHOD
HTTP method (default: GET)
-d DATA, --data=DATA
HTTP request data
--data-file=PATH File contains HTTP request data
-H HEADERS, --header=HEADERS
HTTP request header, can use multiple flags
--header-file=PATH File contains HTTP request headers
-F, --follow-redirects
Follow HTTP redirects
--random-agent Choose a random User-Agent for each request
--auth=CREDENTIAL Authentication credential (e.g. user:password or
bearer token)
--auth-type=TYPE Authentication type (basic, digest, bearer, ntlm, jwt,
oauth2)
--cert-file=PATH File contains client-side certificate
--key-file=PATH File contains client-side certificate private key
(unencrypted)
--user-agent=USER_AGENT
--cookie=COOKIE
Connection Settings:
--timeout=TIMEOUT Connection timeout
--delay=DELAY Delay between requests
--proxy=PROXY Proxy URL (HTTP/SOCKS), can use multiple flags
--proxy-file=PATH File contains proxy servers
--proxy-auth=CREDENTIAL
Proxy authentication credential
--replay-proxy=PROXY
Proxy to replay with found paths
--tor Use Tor network as proxy
--scheme=SCHEME Scheme for raw request or if there is no scheme in the
URL (Default: auto-detect)
--max-rate=RATE Max requests per second
--retries=RETRIES Number of retries for failed requests
--ip=IP Server IP address
Advanced Settings:
--crawl Crawl for new paths in responses
View Settings:
--full-url Full URLs in the output (enabled automatically in
quiet mode)
--redirects-history
Show redirects history
--no-color No colored output
-q, --quiet-mode Quiet mode
Output Settings:
-o PATH, --output=PATH
Output file
--format=FORMAT Report format (Available: simple, plain, json, xml,
md, csv, html, sqlite)
--log=PATH Log file
6.7 gobuster
安装:sudo apt-get install gobuster
使用案例:
1 | |
使用帮助:
1 | |
6.8 dirbuster
// 启动扫描程序
dirnuster
6.9 常见网站文件
1 | |
6.10 网站备份文件
1 | |
7 CMS识别
网站类型:判断网站是独立开发 (网络上唯一的)还是cms二次修改或cms套用模版
敏感文件:网站的登录接口、后台、未被保护的页面、备份文件(www.rar webroot.zip..)
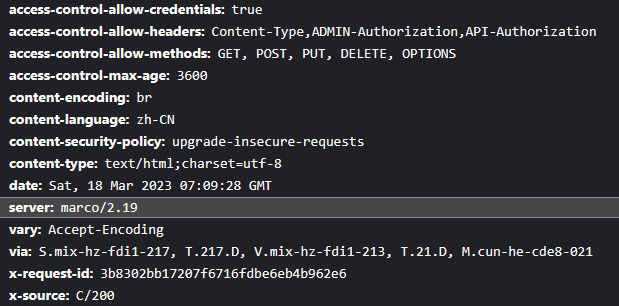
7.1 网站头信息收集
中间件:nginx Apache IIS WebLogic tomcat 。。。
网站主件:js组件jquery、vue
页面的布局:bootstrap
7.1.1 通过浏览器查看
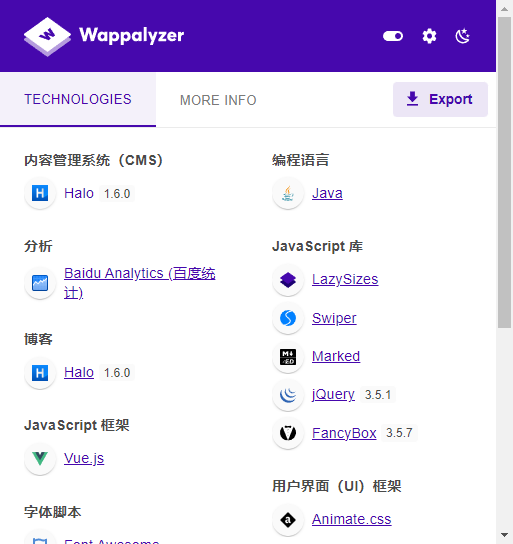
7.1.2 Wappalyzer浏览器插件
支持Google、Edga、Firefox浏览器。
7.1.3 curl获取
使用curl命令查看请求头的信息,中间件的版本。
1 | |
7.2 在线服务CMS识别
7.2.1 云悉web信息收集
<需要登录>
7.2.4 潮汐指纹在线识别系统
<需要登录>
7.2.2 fofa
<需要登录>
7.2.3 whatweb.bugscaner.com
7.2 本地工具
7.2.1 whatweb**(强烈推荐)**
说明:kali自带的CMS识别工具,超级好用。强烈安利!!!!
使用例子:
whatweb https://www.example.com# 扫描过程中显示详细信息
whatweb -v example.com www.example.com
1 | |
7.2.2 御剑WEB指纹识别系统(Windows)
受限于本地CMS指纹库。
7.2.3 TideFinger
网站:https://github.com/TideSec/TideFinger
安装:
2
3
4git clone https://github.com/TideSec/TideFinger.git
# 这里选择的是Python3的版本
cd TideFinger/python3
pip3 install -r requirements.txt
使用例子:
2
3
4
5
6
7
8
9
10
11
12
13# 扫描单个域名
sudo python3 TideFinger.py -u https://cloud.hesc.info
# 使用帮助
┌──(kali㉿kali)-[/opt/TideFinger/python3]
└─$ sudo python3 TideFinger.py
Usage: python3 TideFinger.py -u http://www.123.com [-p 1] [-m 50] [-t 5] [-d 1]
-u: 待检测目标URL地址
-p: 指定该选项为1后,说明启用代理检测,请确保代理文件名为proxys_ips.txt,每行一条代理,格式如: 124.225.223.101:80
-m: 指纹匹配的线程数,不指定时默认为50
-t: 网站响应超时时间,默认为5秒
-d: 是否启用目录匹配式指纹探测(会对目标站点发起大量请求),0为不启用,1为启用,默认为不启用。
7.2.4 onlinetools
网站:https://github.com/iceyhexman/onlinetools
说明:数据不准确,扫描有时候没有结果返回。
本地安装:
2
3
4git clone https://github.com/iceyhexman/onlinetools.git
cd onlinetools
pip3 install -r requirements.txt
nohup python3 main.py &Docker安装:
2
3
4git clone https://github.com/iceyhexman/onlinetools.git
cd onlinetools
docker build -t onlinetools .
docker run -d -p 8000:8000 onlinetools使用:
浏览器打开:http://localhost:8000/
7.2.5 TScan
网站:https://github.com/dyboy2017/TScan
说明:数据不准确,扫描有时候没有结果返回。
安装:
2
3git clone https://github.com/dyboy2017/TScan.git
cd TScan
pip3 install -r requirements.txt启动web服务:
python3 manage.py runserver 0.0.0.0:8081使用:
浏览器打开:http://localhost:8081
7.2.6 Github.com搜索CMS工具
8 敏感文件搜索
8.1 Github.com
8.1.1 Github仓库信息搜索
仓库标题含有关键字bilibili
in:name bilbili
仓库描述搜索含有bilbili关键字
in:descripton bilbili
README文件搜索含有bilbili关键字
>in:readme bilbili
8.1.2 搜索某些系统的密码
https://github.com/search?q=smtp+58.com+password+3306&type=Code
8.1.3 通过Google搜索github.com
1 | |
相关文章:
https://blog.csdn.net/qq_36119192/article/details/99690742
http://www.361way.com/github-hack/6284.html
https://docs.github.com/cn/github/searching-for-information-on-github/searching-code
8.2 Google-hacking
1 | |
8.3 Github.com信息泄露监控
定期扫描github.com是否有泄露的数据。
https://github.com/0xbug/Hawkeye
8.4 JS敏感文件收集
8.4.1 SecretFinder
网站:https://github.com/m4ll0k/SecretFinder
说明:SecretFinder 是一个基于LinkFinder的 python 脚本,用于发现 JavaScript 文件中的敏感数据,如 apikeys、accesstoken、授权、jwt 等。它通过将 jsbeautifier for python 与相当大的正则表达式结合使用来实现。正则表达式由四个小的正则表达式组成。这些负责查找和搜索 js 文件上的任何内容。
输出以 HTML 或纯文本形式给出。
使用例子
2
3
4
5
6$ git clone https://github.com/m4ll0k/SecretFinder.git secretfinder
$ cd secretfinder
$ pip3 install -r requirements.txt
$ python3 SecretFinder.py
usage: SecretFinder.py [-h] [-e] -i INPUT [-o OUTPUT] [-r REGEX] [-b] [-c COOKIE] [-g IGNORE] [-n ONLY] [-H HEADERS] [-p PROXY]
SecretFinder.py: error: the following arguments are required: -i/--input、使用帮助
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27usage: SecretFinder.py [-h] [-e] -i INPUT [-o OUTPUT] [-r REGEX] [-b]
[-c COOKIE] [-g IGNORE] [-n ONLY] [-H HEADERS]
[-p PROXY]
optional arguments:
-h, --help show this help message and exit
-e, --extract Extract all javascript links located in a page and
process it
-i INPUT, --input INPUT
Input a: URL, file or folder
-o OUTPUT, --output OUTPUT
Where to save the file, including file name. Default:
output.html
-r REGEX, --regex REGEX
RegEx for filtering purposes against found endpoint
(e.g: ^/api/)
-b, --burp Support burp exported file
-c COOKIE, --cookie COOKIE
Add cookies for authenticated JS files
-g IGNORE, --ignore IGNORE
Ignore js url, if it contain the provided string
(string;string2..)
-n ONLY, --only ONLY Process js url, if it contain the provided string
(string;string2..)
-H HEADERS, --headers HEADERS
Set headers ("Name:Value\nName:Value")
-p PROXY, --proxy PROXY
Set proxy (host:port)使用例子
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# 扫描整个域及其JS文件
$ python3 SecretFinder.py -i http://dghskq.com/ -e
# 扫描网站中的JS文件,使用默认正则表达式查找敏感数据,并将结果保存到results.html
$ python3 SecretFinder.py -i https://example.com/1.js -o results.html
# 忽略由提供的某些js文件(如外部库)
$ python3 SecretFinder.py -i https://example.com/ -e -g 'jquery;bootstrap;api.google.com'
# 使用自定义正则表达式扫描js文件
$ python3 SecretFinder.py -i https://example.com/1.js -o cli -r 'apikey=my.api.key[a-zA-Z]+'
# 添加标头、代理和 cookie进行扫描
$ python3 SecretFinder.py -i https://example.com/ -e -o cli -c 'mysessionid=111234' -H 'x-header:value1\nx-header2:value2' -p 127.0.0.1:8080 -r 'apikey=my.api.key[a-zA-Z]+'
#### 8.4.2 JSFinder
- [x] **网站:**https://github.com/Threezh1/JSFinder
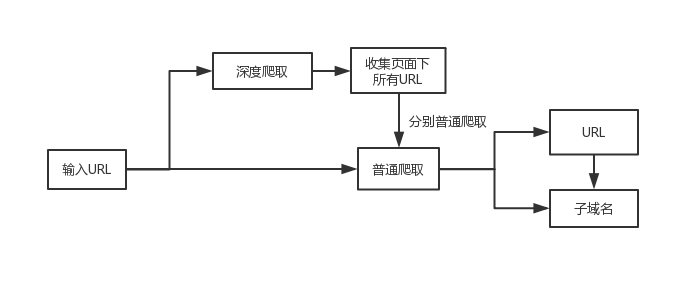
- [x] **说明:**JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。提取URL的正则部分使用的是LinkFinder。
JSFinder获取URL和子域名的方式:
- [x] **安装:**
```shell
git clone https://github.com/Threezh1/JSFinder.git
使用例子
简单爬取
1
python JSFinder.py -u http://www.mi.com深度爬取
1
python JSFinder.py -u http://www.mi.com -d批量指定URL/指定JS
1
2
3
4指定URL:
python JSFinder.py -f text.txt
指定JS:
python JSFinder.py -f text.txt -j其他
1
2
3
4
5
6-c 指定cookie来爬取页面 例:
python JSFinder.py -u http://www.mi.com -c "session=xxx"
-ou 指定文件名保存URL链接 例:
python JSFinder.py -u http://www.mi.com -ou mi_url.txt
-os 指定文件名保存子域名 例:
python JSFinder.py -u http://www.mi.com -os mi_subdomain.t
8.4.3 Packer-Fuzzer
安装
1
2
3
4
5
6
7# 安装nodejs
$ sudo apt-get install nodejs && sudo apt-get install npm
# 下载安装包
$ git clone https://github.com/rtcatc/Packer-Fuzzer.git
$ cd Packer-Fuzzer
# 安装依耐
$ pip3 install -r requirements.txt --break-system-packages参数介绍
您可以使用python3 PackerFuzzer.py [options]命令来运行本工具,options内容表述如下:
参数 说明 -h(–help) 帮助命令,无需附加参数,查看本工具支持的全部参数及其对应简介; -u(–url) 要扫描的网站网址路径,为必填选项,例如:-u https://demo.poc-sir.com; -c(–cookie) 附加cookies内容,可为空,若填写则将全局传入,例如:-c “POC=666;SIR=233”; -d(–head) 附加HTTP头部内容,可为空,若填写则将全局传入,默认为Cache-Control:no-cache,例如:-d “Token:3VHJ32HF0”; -l(–lang) 语言选项,当为空时自动选择系统对应语言选项,若无对应语言包则自动切换至英文界面。可供选择的语言包有:简体中文(zh)、法语(fr)、西班牙语(es)、英语(en)、日语(ja),例如:-l zh; -t(–type) 分为基础版和高级版,当为空时默认使用基础版。高级版将会对所有API进行重新扫描并模糊提取API对应的参数,并进行:SQL注入漏洞、水平越权漏洞、弱口令漏洞、任意文件上传漏洞的检测。可使用adv选项进入高级版,例如:-t adv; -p(–proxy) 全局代理,可为空,若填写则全局使用代理IP,例如:-p https://hack.cool:8080; -j(–js) 附加JS文件,可为空,当您认为还有其他JS文件需要本工具分析时,可使用此选项,例如:-j https://demo.poc-sir.com/js/index.js,https://demo.poc-sir.com/js/vue.js; -b(–base) 指定API中间部分(例如某API为:https://demo.poc-sir.com/v1_api/login 时,则其basedir为:v1_api),可为空,当您认为本工具自动提取的basedir不准确时,可使用此选项,例如:-b v1_api; -r(–report) 指定生成的报告格式,当为空时默认生成HTML和DOC格式的报告。可供选择的报告格式有:html、doc、pdf、txt,例如:-r html,pdf; -e(–ext) 是否开启扩展插件选项,本工具支持用户自我编写插件并存入ext目录(如何编写请参考对应目录下demo.py文件)。默认为关闭状态,当用户使用on命令开启时,本工具将会自动执行对应目录下的插件,例如:-e on; -f(–flag) SSL连接安全选项,当为空时默认关闭状态,在此状态下将会阻止一切不安全的连接。若您希望忽略SSL安全状态,您可使用1命令开启,将会忽略一切证书错误,例如:-f 1; -s(–silent) 静默选项,一旦开启则一切询问YES或NO的操作都将自动设置为YES,并且参数后的内容便是本次扫描报告的名称(自定义报告名),可用于无人值守、批量操作、插件调用等模式,例如:-s Scan_Task_777。 –st(–sendtype) 请求方式选项,目前本选项支持POST和GET参数,一旦开启则将会使用对应的请求方式扫描所有的API,若不开启将会通过HTTP状态码来进行智能请求。 –ct(–contenttype) Content-Type选项,可通过此选项自定义扫描时的HTTP请求头中的Content-Type参数内容,若不开启将会通过HTTP状态码来进行智能请求。 –pd(–postdata) POST内容选项,可通过此选项自定义扫描时的POST请求内容(所有的扫描都将会使用此内容,仅对POST场景有效),若不开启将会通过HTTP状态码来进行智能请求。 –ah(–apihost) Api域名选项,可通过此选项自定义扫描时所有的API请求域名,例如:api部分(从JS中提取到的API路径)为/v1/info,扫描的url(-u –url参数传入内容,扫描的网页)为http://exp.com/,当apihost参数传入https://pocsir.com:777/则此时的API为https://pocsir.com:777/v1/info而不是http://exp.com/v1/info,用于api与前端不同域名或服务器等场景。 –fe(–fileext) Api扩展名选项,可通过此选项对所有API都添加特定的扩展名,以便应对在提取API时出现扩展名提取缺失的情况,例如:当提取到的API为https://pocsir.com:777/v1/info时,传入--fe .json则工具将会自动将API转化成https://pocsir.com:777/v1/info.json进行扫描及检测。 使用例子
1
python3 PackerFuzzer.py -u https://cloud.hesc.info -r html,pdf;
9 社交账号信息搜索
基础:
QQ群 QQ手机号
微信群
脉脉招聘
boss招聘
社工库:
电报Telegram群
11 SSL/TLS证书查询
11.1 在线网站查询
11.2 本地工具GetDomainsBySSL
网站
1
https://github.com/Oritz/GetDomainsBySSL安装
1
2
3$ git clone https://github.com/Oritz/GetDomainsBySSL.git
$ cd GetDomainsBySSL
$ pip3 install lxml使用
1
$ python3 GetDomainsBySSL.py hesc.info注意点:
- 需要能正常访问 Google
- Windows 没有 OpenSSL 命令
12 找真实IP地址
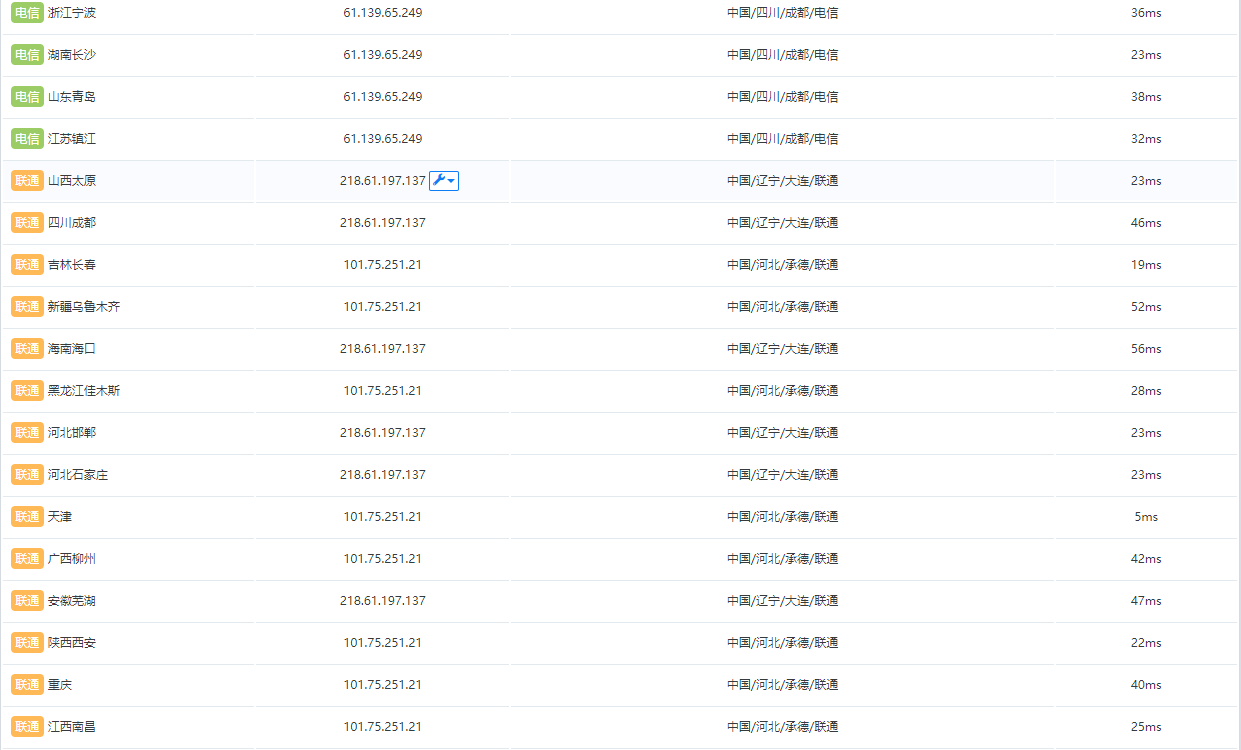
12.1 如何判断是否使用CND
使用超级ping,ping域名查看解析的ip地址是否一致。
12.2 dns历史绑定记录
通过以下这些网站可以访问dns的解析,有可能存在未有绑cdn之前的记录。
https://dnsdb.io/zh-cn/ # DNS查询
https://x.threatbook.cn/ # 微步在线
http://viewdns.info/ # DNS、IP等查询
https://tools.ipip.net/cdn.php # CDN查询IP
12.3 通子域名获取真实IP
获取子域名信息:
https://securitytrails.com/list/apex_domain/根域名
https://tool.chinaz.com/subdomain/hesc.info
补充:子域名穷举工具
批量解析子域名IP地址
12.4 通过国外dns获取真实IP
全世界DNS地址:
http://www.ab173.com/dns/dns_world.php
http://whoisrequest.com/history/ dwq
https://completedns.com/dns-history/
https://who.is/domain-history/
http://research.domaintools.com/research/hosting-history/ http://site.ip138.com/
http://viewdns.info/iphistory/
http://toolbar.netcraft.com/site_report?url= https://securitytrails.com/
12.5 ico图标通过空间搜索找真实ip
12.5.1 fofa
下载ico图标,放到fofa中进行识别,
通过fofa搜图标
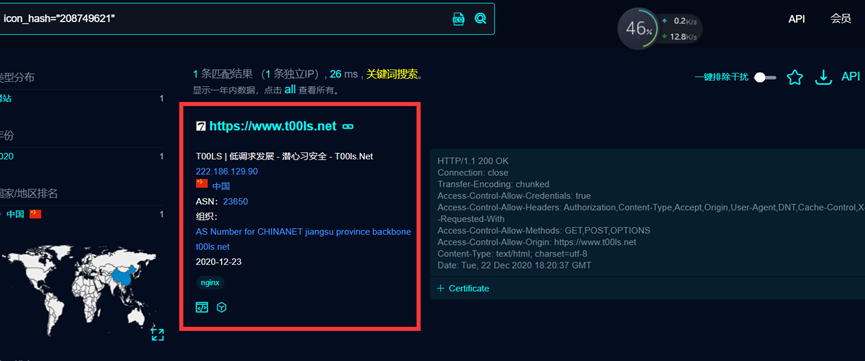
通过这样查询 快速定位资源 查看端口是否开放 这里没有开放,后续测试开放的端口和绑定host进行访问测试
12.5.2 zoomeye

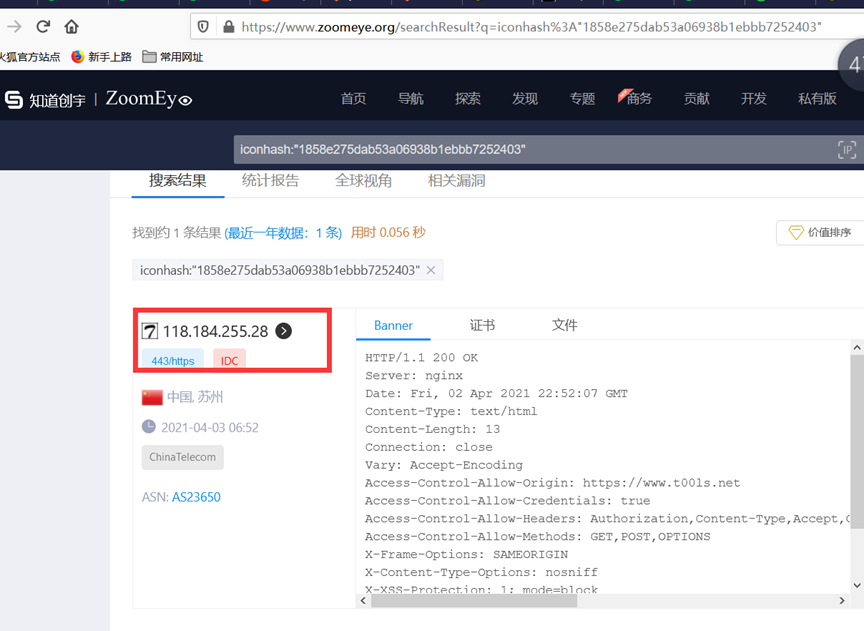
开放端口测试,绑定hosts测试
12.6 fofa搜索真实IP
domain=”t00ls.net” 302一般是cdn
12.7 通过censys找真实ip
需要注册账号,查询次数多了需要登录。
Censys工具就能实现对整个互联网的扫描,Censys是一款用以搜索联网设备信息的新型搜索引擎,能够扫描整个互联网,Censys会将互联网所有的ip进行扫面和连接,以及证书探测。
若目标站点有https证书,并且默认虚拟主机配了https证书,我们就可以找所有目标站点是该https证书的站点。
通过协议查询
1 | |
12.8 360测绘中心
12.9 利用SSL证书寻找真实IP
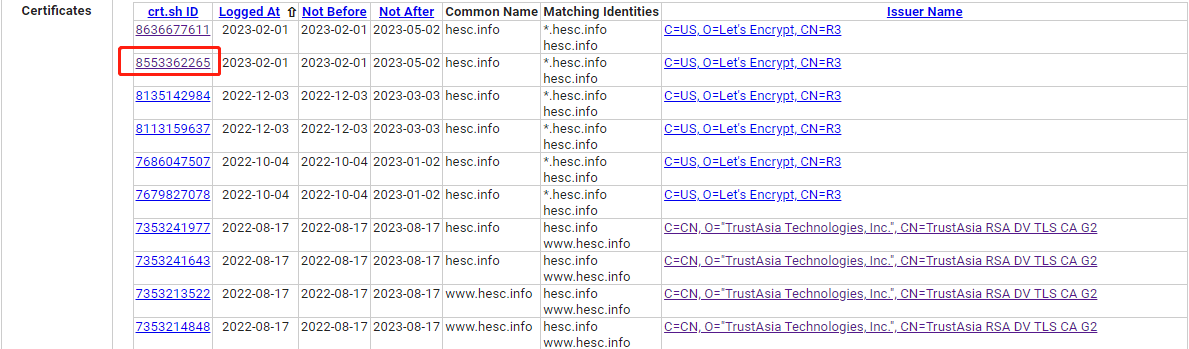
找到域名证书信息,点击crt.sh id进入证书详细页面,通过证书HASH搜索IP
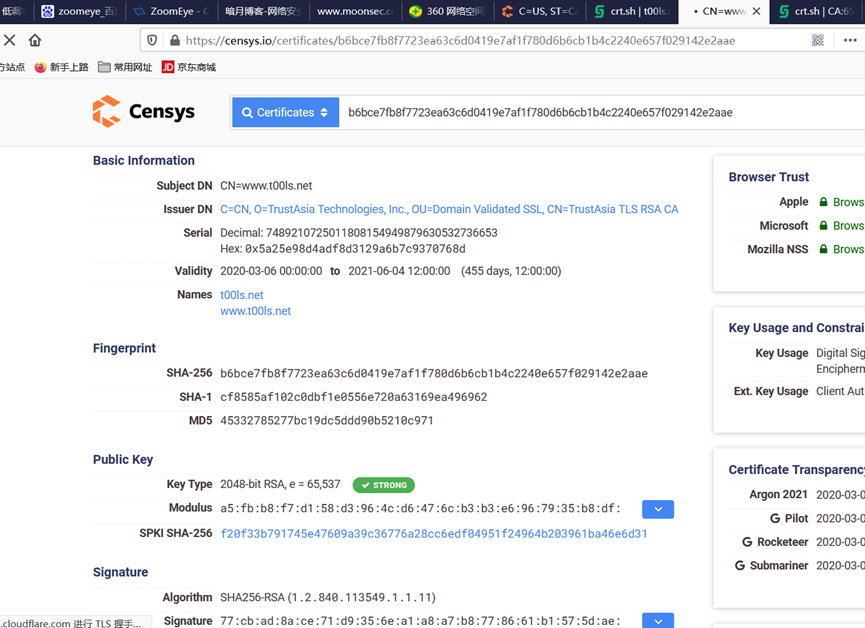
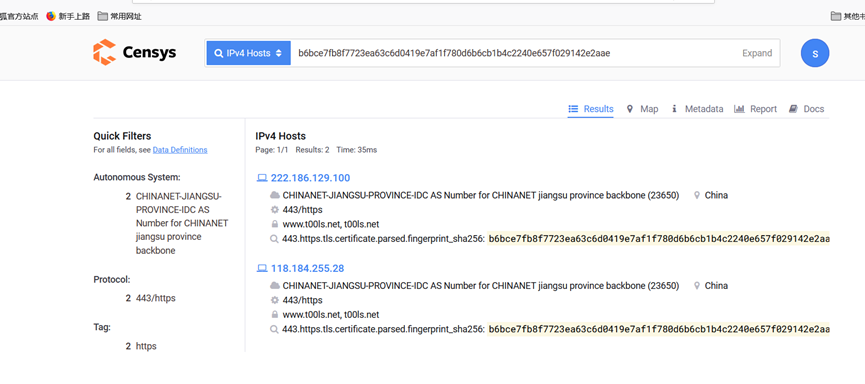
12.10 邮箱获取真实IP
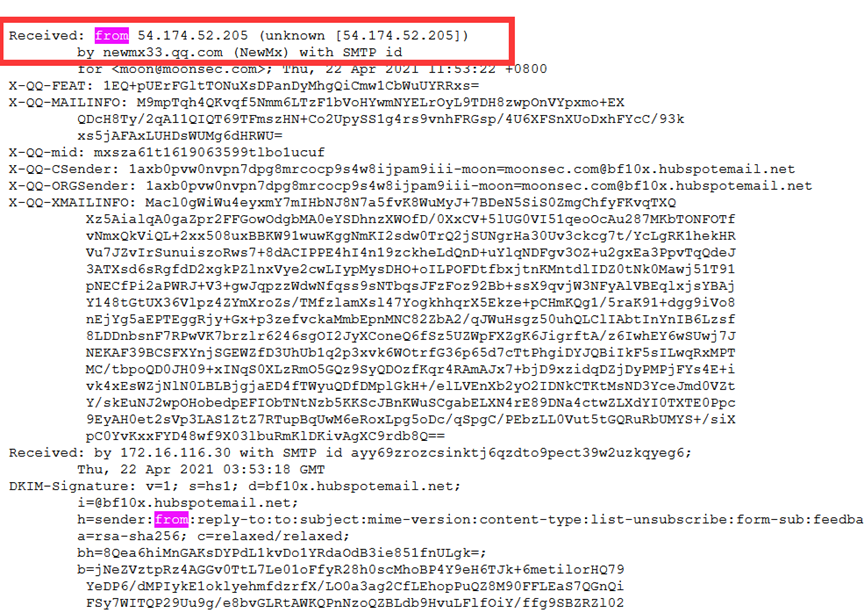
网站在发信的时候,会附带真实的IP地址 进入邮箱 查看源文件头部信息 选择from
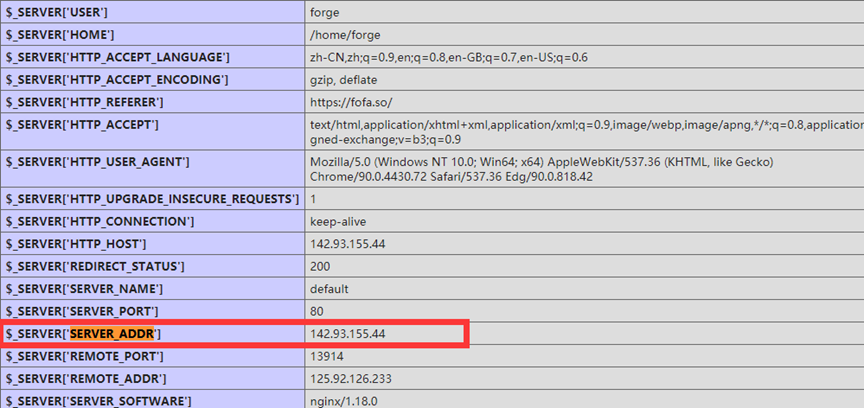
12.11 网站敏感文件获取真实IP
- 文件探针
- phpinfo
- 网站源代码
- 信息泄露
- GitHub信息泄露
- js文件
12.12 F5 LTM解码法
当服务器使用F5 LTM做负载均衡时,通过对set-cookie关键字的解码真实ip也可被获取,
例如:Set-Cookie: BIGipServerpool_8.29_8030=487098378.24095.0000,先把第一小节的十进制数即487098378取出来,然后将其转为十六进制数1d08880a,接着从后至前,以此取四位数出来,也就是0a.88.08.1d,最后依次把他们转为十进制数10.136.8.29,也就是最后的真实ip。
rverpool-cas01=3255675072.20480.0000; path=/
3255675072 转十六进制 c20da8c0 从右向左取 c0a80dc2 转10进制 192 168 13 194
12.13 APP获取真实IP
如果网站有app,使用Fiddler或BurpSuite抓取数据包 可能获取真实IP
模拟器 mimi模拟器抓包
12.14 小程序获取真实IP
12.15 配置不当获取真实IP
在配置CDN的时候,需要指定域名、端口等信息,有时候小小的配置细节就容易导致CDN防护被绕过。
- 案例1:为了方便用户访问,我们常常将
www.test.com和test.com解析到同一个站点,而CDN只配置了www.test.com,通过访问test.com,就可以绕过CDN了。 - 案例2:站点同时支持http和https访问,CDN只配置https协议,那么这时访问http就可以轻易绕过。
12.16 banner
获取目标站点的banner,在全网搜索引擎搜索,也可以使用AQUATONE,在Shodan上搜索相同指纹站点。
可以通过互联网络信息中心的IP数据,筛选目标地区IP,遍历Web服务的banner用来对比CDN站的banner,可以确定源IP。
欧洲:http://ftp.ripe.net/pub/stats/ripencc/delegated-ripencc-latest
北美:https://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest
亚洲:ftp://ftp.apnic.net/public/apnic/stats/apnic/delegated-apnic-latest
非洲:ftp://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-latest
拉美:ftp://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest
获取CN的IP
http://www.ipdeny.com/ipblocks/data/countries/cn.zone
例如:
找到目标服务器 IP 段后,可以直接进行暴力匹配 ,使用zmap、masscan 扫描 HTTP banner,然后匹配到目标域名的相同 banner
1 | |
使用zmap的banner-grab对扫描出来80端口开放的主机进行banner抓取。
1 | |
根据网站返回包特征,进行特征过滤
1 | |
1、ZMap号称是最快的互联网扫描工具,能够在45分钟扫遍全网
2、Masscan号称是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。
https://github.com/robertdavidgraham/masscan
12.17 长期关注
在长期渗透的时候,设置程序每天访问网站,可能有新的发现。每天零点 或者业务需求增大 它会换ip 换服务器的。
12.18 流量攻击
发包机可以一下子发送很大的流量。
这个方法是很笨,但是在特定的目标下渗透,建议采用。
cdn除了能隐藏ip,可能还考虑到分配流量,
不设防的cdn 量大就会挂,高防cdn 要大流量访问。
经受不住大流量冲击的时候可能会显示真实ip。
站长->业务不正常->cdn不使用->更换服务器。
12.19 被动获取
被动获取就是让服务器或网站主动连接我们的服务器,从而获取服务器的真实IP
如果网站有编辑器可以填写远程url图片,即可获取真实IP
如果存在ssrf漏洞 或者xss让服务器主动连接我们的服务器均 可获取真实IP。
12.20 扫全网获取真实IP
https://github.com/superfish9/hackcdn
https://github.com/boy-hack/w8fuckcdn
13 使用Goby扫描资产
14 ARL(Asset Reconnaissance Lighthouse)资产侦察灯塔系统
网站:https://github.com/TophantTechnology/ARL
支持docker部署。
00 补充点
查找厂商ip段
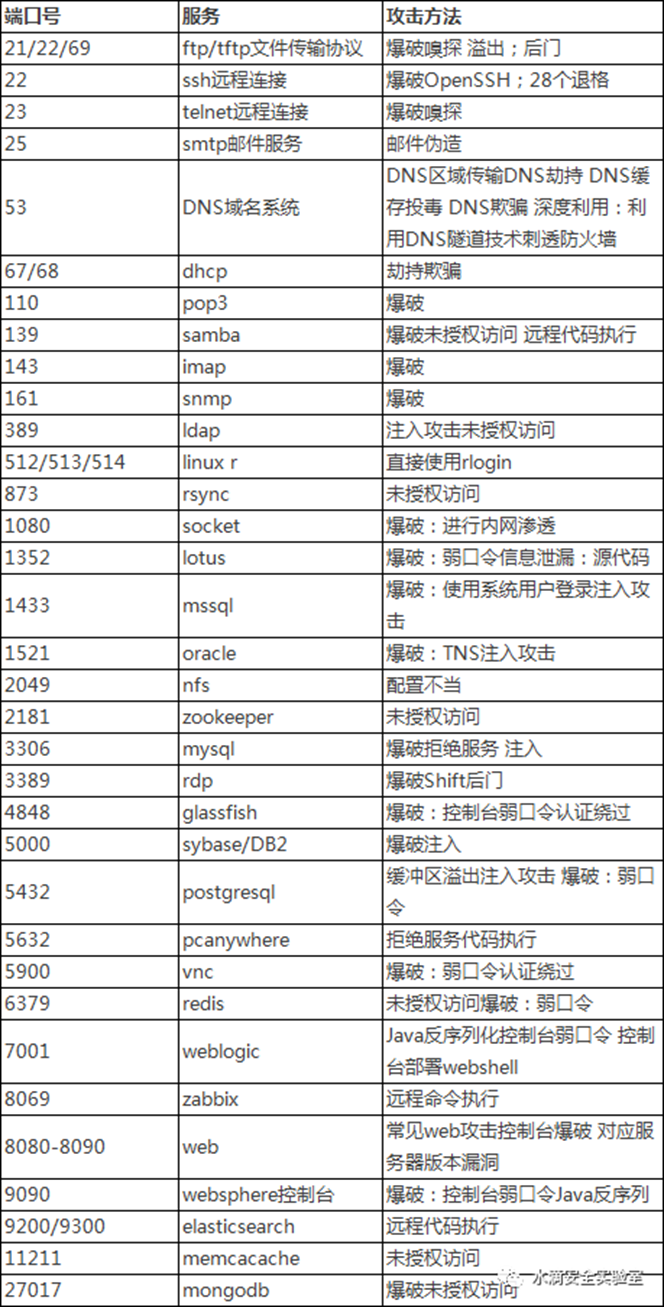
常见的端口和攻击方法
渗透测试中常用的windows命令
1 | |